Đến tháng 7/2024, câu hỏi "thế hệ mô hình ngôn ngữ tiếp theo sẽ lấy dữ liệu huấn luyện AI từ đâu" không còn là chuyện lý thuyết. Văn bản công khai trên internet đã gần đạt ngưỡng bão hòa, trong khi nhu cầu dữ liệu huấn luyện AI chất lượng cao do con người tạo ra đã vượt nguồn cung dự báo. Dữ liệu tổng hợp, tức văn bản do chính các mô hình ngôn ngữ khác sinh ra, được nhiều bên đưa ra như câu trả lời hiển nhiên.
Một bài báo công bố trong tháng đó trên arXiv, "Regurgitative Training: The Value of Real Data in Training Large Language Models" của Zhang, Qiao, Yang và Wei, đặt câu hỏi: dữ liệu huấn luyện AI tổng hợp có thật sự hiệu quả không? Kết quả không dễ chịu cho bất kỳ đội ngũ nào đặt lộ trình AI của mình vào những lối tắt tổng hợp, và đặc biệt có ý nghĩa với thị trường mới nổi như Việt Nam. (Xem thêm góc nhìn của chúng tôi trong bài Từ dữ liệu thô đến lợi thế chiến lược.)
Thí nghiệm, ngắn gọn
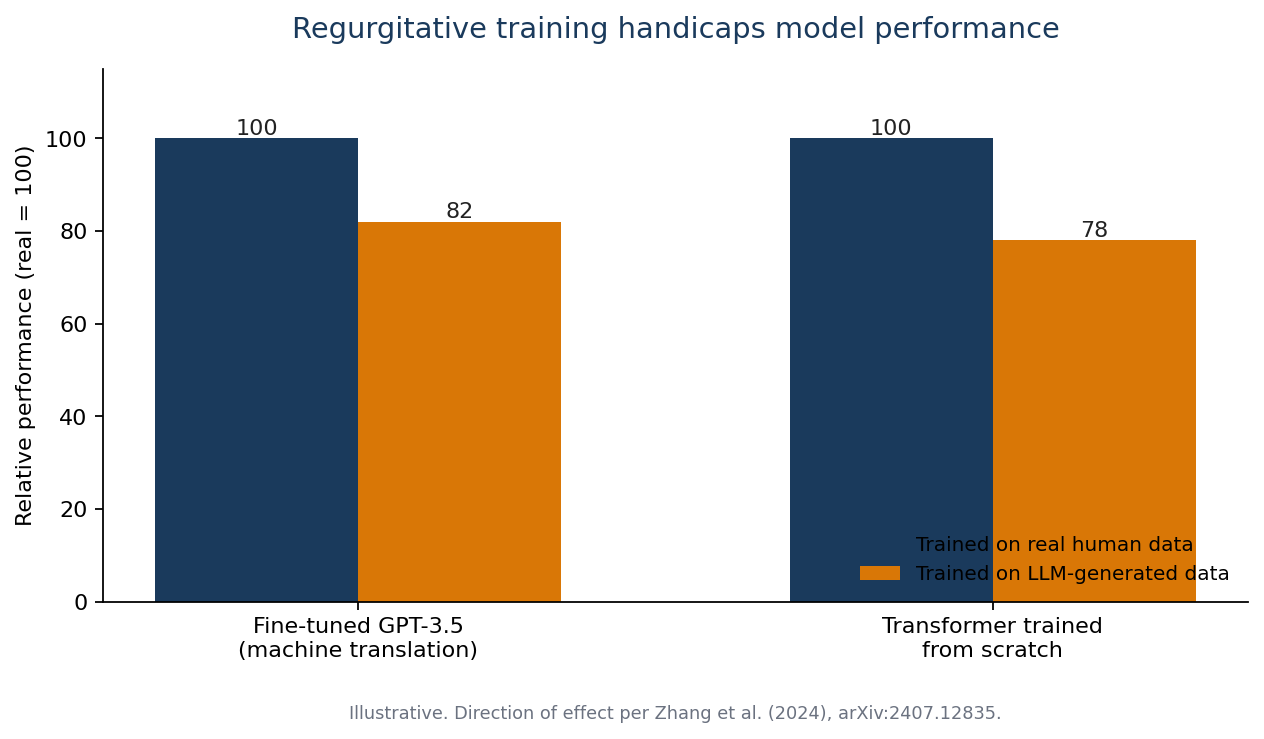
Nhóm tác giả thực hiện hai thí nghiệm song song về dữ liệu huấn luyện AI. Họ fine-tune GPT-3.5 trên tác vụ dịch máy với hai loại dữ liệu: bản dịch do con người tạo và văn bản do các LLM khác sinh ra. Sau đó họ huấn luyện thêm các mô hình transformer từ đầu với cùng điều kiện. Trong cả hai trường hợp, mô hình học từ dữ liệu huấn luyện AI do máy sinh ra đều cho kết quả kém hơn so với mô hình học từ dữ liệu của con người.
Bản thân kết luận này không bất ngờ. Điều đáng nói là độ lớn của khoảng cách và nguyên nhân tạo ra nó. Các tác giả chỉ ra hai cơ chế trong dữ liệu huấn luyện AI tổng hợp. Thứ nhất khá đơn giản: dữ liệu do LLM sinh ra có tỷ lệ lỗi cao hơn dữ liệu tương ứng do người tạo.
Thứ hai thú vị hơn: đầu ra của LLM có độ đa dạng từ vựng thấp hơn. Văn bản máy, theo một nghĩa nào đó, lặp lại chính nó nhiều hơn con người. Học trên phân phối hẹp đó, mô hình kế thừa luôn sự hẹp đó.
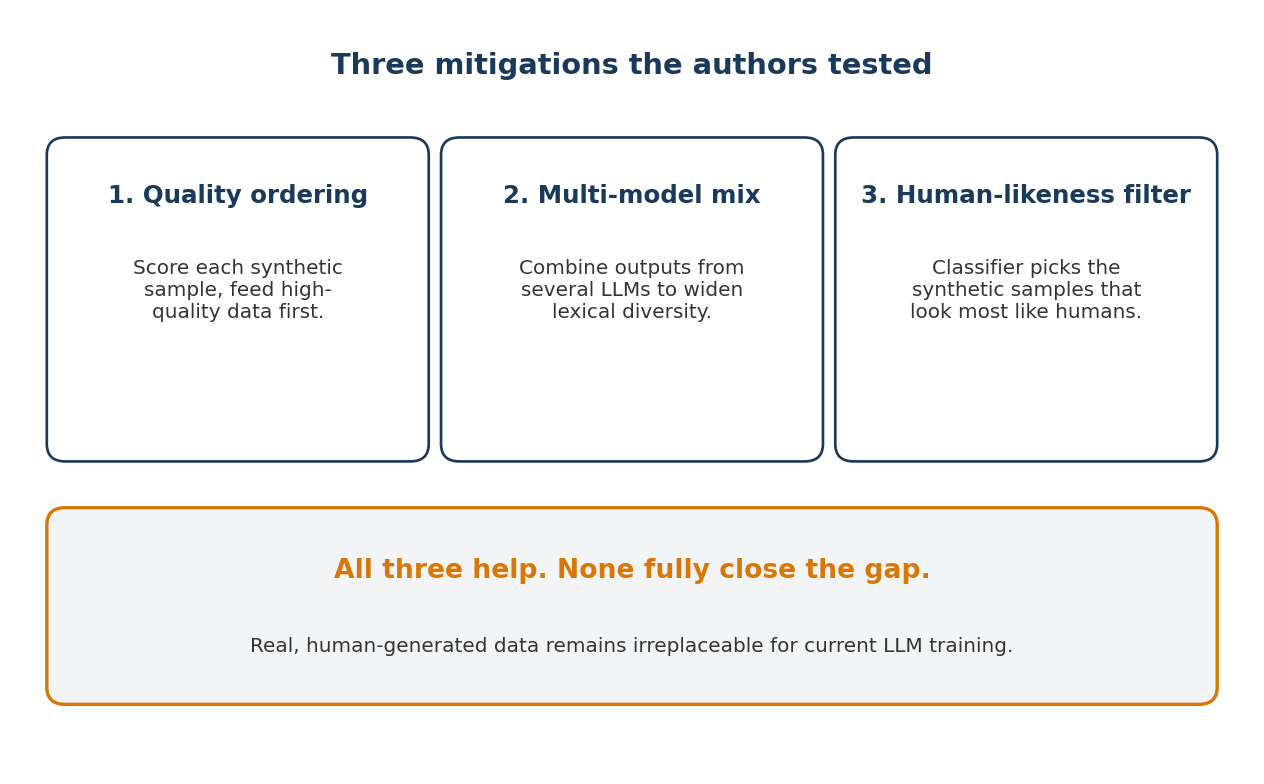
Nhóm không dừng ở chẩn đoán. Họ thử ba phương án khắc phục. Họ xây dựng một thước đo chất lượng và cho mô hình học các mẫu máy có chất lượng cao trước. Họ trộn đầu ra từ nhiều LLM khác nhau để mở rộng phổ từ vựng.
Họ huấn luyện một bộ phân loại để phát hiện mẫu tổng hợp nào trông giống người nhất và sắp xếp thứ tự huấn luyện theo đó. Mỗi phương án có cải thiện. Không phương án nào đóng được hoàn toàn khoảng cách. Kết luận của bài báo thẳng thắn: dữ liệu huấn luyện AI thực do con người tạo "không thể dễ dàng được thay thế bằng dữ liệu tổng hợp do LLM sinh ra.
Vì sao điều này quan trọng với dữ liệu huấn luyện AI tiếng Việt
Trong tiếng Anh, nguồn cung văn bản thật của con người là rất lớn. Một đội xây mô hình nền tảng có thể bù đắp phần lớn điểm yếu của dữ liệu huấn luyện AI tổng hợp bằng khối lượng tuyệt đối. Trong tiếng Việt, khối lượng đó không tồn tại.
Lượng văn bản tiếng Việt được lập chỉ mục trên web chỉ là một phần nhỏ so với tiếng Anh, lại có tỷ lệ trùng lặp cao, nhiều phần là dịch máy hoặc văn bản tự sinh. Phân phối gốc mà mọi mô hình hướng tiếng Việt đang dựa vào đã hẹp sẵn. Bối cảnh khan hiếm dữ liệu nói chung cũng đã được chúng tôi đề cập trong bài 5 sai lầm tra cứu doanh nghiệp Việt Nam.
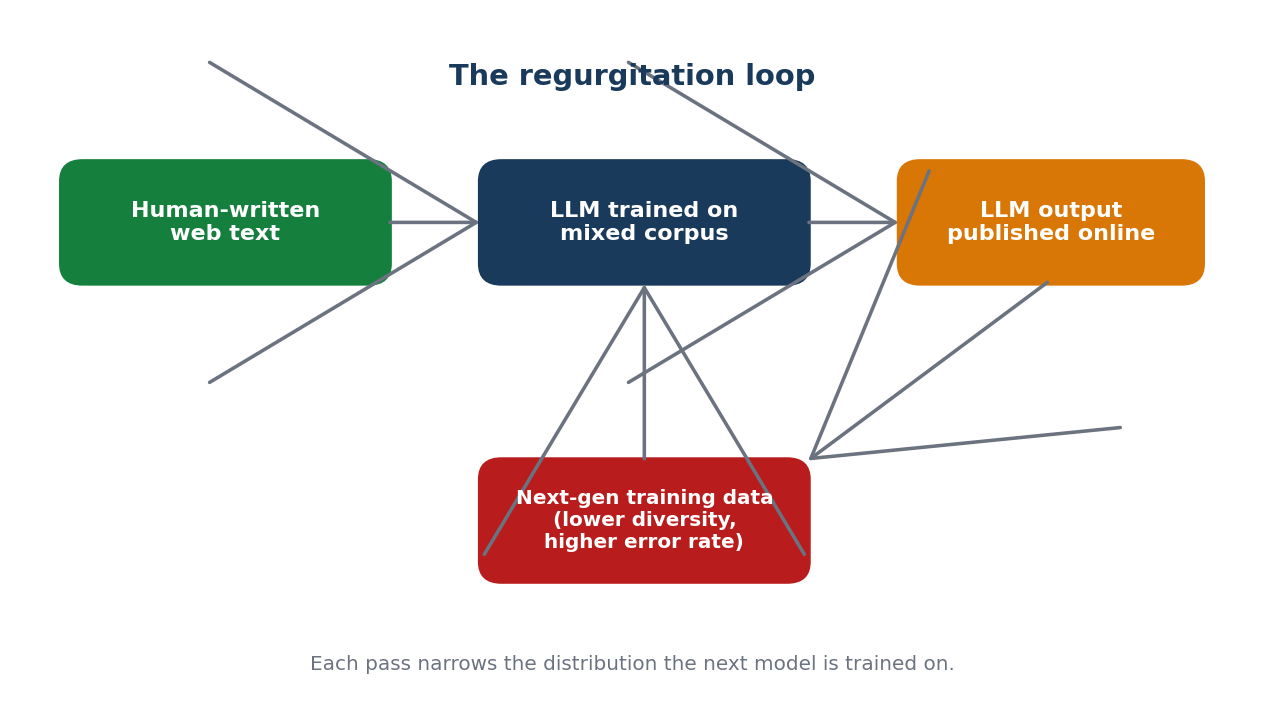
Nếu chấp nhận kết quả của nghiên cứu, hệ quả cho công việc dữ liệu huấn luyện AI tiếng Việt khá khó chịu. Lối tắt dữ liệu tổng hợp làm trầm trọng thêm vấn đề đa dạng vốn có, thay vì giải nó. Mỗi thế hệ đầu ra mô hình được thêm vào tập huấn luyện lại thu hẹp phân phối thêm một chút. Hiệu ứng "regurgitation" vốn nhẹ với tiếng Anh, lại trở nên gắt hơn ở môi trường ngôn ngữ nhỏ.
Logic này cũng áp dụng cho fine-tune và alignment. Dữ liệu preference cho RLHF lấy từ đầu ra máy sẽ phản ánh sở thích của máy. Các chỉnh sửa hallucination do LLM soạn thảo có xu hướng lặp lại đúng những điểm mù của LLM. Mẫu SFT do mô hình tự viết thường nghe rất trôi chảy nhưng bỏ sót sắc thái văn hóa mà một người chú thích sẽ bắt được ngay. Sai số tích lũy qua từng vòng dữ liệu huấn luyện AI chất lượng thấp.
Có những đặc điểm rất cụ thể của tiếng Việt liên quan trực tiếp đến điều này. Sáu thanh điệu, phương ngữ Bắc, Trung, Nam có vốn từ khác nhau ở mức đo đếm được, hiện tượng pha trộn ngôn ngữ với từ vay tiếng Anh và Hán Việt trong các lĩnh vực chuyên môn, và một thực tế là trên mạng xã hội phần lớn văn bản bị mất dấu.
Mỗi đặc điểm đó mang thông tin thực, và các LLM hiện nay chưa tái tạo lại được một cách ổn định. Một tập huấn luyện tổng hợp do mô hình đã làm phẳng các đặc điểm này viết ra sẽ huấn luyện thế hệ mô hình sau làm phẳng thêm nữa.
Việt Nam đang xây gì cho dữ liệu huấn luyện AI
Hạ tầng trong nước cho dữ liệu huấn luyện AI do con người tạo đã bắt đầu hình thành. Các nền tảng crowdsourcing, hợp tác với đại học, và một vài đơn vị chuyên biệt nhỏ đang cạnh tranh trong một thị trường mà năm năm trước về cơ bản chưa có.
Một ví dụ là QuestLab, một nền tảng crowdsourcing xây dựng tại Việt Nam, tự mô tả trên trang chủ là "nền tảng thu thập dữ liệu cộng đồng số 1 Việt Nam" với mạng lưới hơn 50.000 cộng tác viên đã xác thực.
Danh mục dịch vụ công bố của họ bao trùm đúng những khoảng trống mà Zhang et al. chỉ ra: dữ liệu preference cho RLHF và reward modeling, kiểm định ảo giác (hallucination audits) đối chiếu với nguồn tin cậy, tập dữ liệu instruction cho SFT, gán nhãn ảnh và video.
Họ cũng cung cấp OCR cho tài liệu tiếng Việt viết tay và có cấu trúc, thu âm giọng nói đa vùng miền, và kiểm duyệt nội dung. Họ cũng làm nghiên cứu thị trường và dịch vụ thực địa như kiểm tra điểm bán và mystery shopping, một lời nhắc hữu ích rằng hạ tầng dữ liệu con người hiếm khi chạy được nếu chỉ dựa vào nhu cầu AI.
Điểm cần ghi nhận một cách khách quan: các nền tảng kiểu này hoạt động được ở quy mô lớn là nhờ ngồi trên một mạng lưới cộng tác viên phân tán. Một tệp 50.000 cộng tác viên không phải con số marketing đối với một đội AI.
Nó là ràng buộc thực tế về số luồng gán nhãn chạy song song được, số phương ngữ một bộ dữ liệu giọng nói có thể bao phủ, và tốc độ một đợt kiểm định hallucination có thể hoàn thành. Các đối thủ trong khu vực Đông Nam Á cũng vận hành theo logic tương tự.
Nếu một đội AI Việt Nam chỉ ngân sách cho compute và đường ống dữ liệu tổng hợp, coi chi cho dữ liệu con người là khoản tùy chọn, bằng chứng cho thấy đội đó đang ở thế bất lợi cấu trúc so với đội không làm vậy. Đội mua dữ liệu có thể tham khảo cách kỷ luật trong quy trình mua sắm từ bài Xác minh nhà cung cấp Việt Nam 2026.
QuestLab là một trong nhiều bên tham gia. Quan điểm ở đây không phải là một nhà cung cấp đơn lẻ nào đó giải quyết được vấn đề dữ liệu huấn luyện AI mà bài báo nêu ra, mà là bài báo đã thay đổi bài toán chi phí cho phía mua.
Câu hỏi khó hơn
Ba phương án giảm thiểu mà các tác giả thử đáng được đọc kỹ, vì đó cũng là những phương án mà phần lớn đội AI doanh nghiệp tìm đến khi ngân sách dữ liệu người bị cắt. Cho dữ liệu tổng hợp chất lượng cao học trước. Trộn đầu ra từ nhiều họ mô hình. Lọc theo mức độ giống người.
Cả ba đều hợp lý. Cả ba đều có ích. Không phương án nào là thay thế hoàn toàn. Cách đọc hợp lý nhất là dữ liệu huấn luyện AI tổng hợp là phần bổ trợ hữu ích cho dữ liệu thật, không phải vật thay thế.
Cách đặt vấn đề này không mới. Nó cộng hưởng với kết quả của Shumailov et al. (Nature, 2024) về "model collapse" khi huấn luyện đệ quy, và những công trình trước về tính đa dạng dữ liệu trong dịch máy. Cái Zhang et al. bổ sung là một thí nghiệm sạch sẽ, có kiểm soát, trên một lớp mô hình mà thị trường đang thật sự triển khai, kèm phát biểu rõ ràng rằng các phương án giảm thiểu cho dữ liệu huấn luyện AI tổng hợp đã công bố vẫn chưa đủ.
3 chi phí ẩn các đội AI Việt Nam cần tính vào
Quay lại thực tế mua sắm, ba chi phí cụ thể xuất hiện khi đội AI phụ thuộc quá mức vào dữ liệu huấn luyện AI tổng hợp, và đội Việt Nam nên tính vào ngân sách.
Chi phí một: suy giảm độ chính xác ở metric hạ nguồn. Tỷ lệ lỗi cao hơn trong dữ liệu huấn luyện AI tổng hợp chảy thẳng vào đầu ra mô hình. Với các ứng dụng nơi độ chính xác quan trọng (pháp lý, y tế, tài chính), suy giảm này là chi phí trực tiếp cho hiệu đính, hoàn tiền và mất niềm tin.
Chi phí hai: sự nhạt nhòa về từ vựng và văn hóa. Sự sụp đổ đa dạng mà các tác giả ghi nhận có nghĩa các mô hình tiếng Việt huấn luyện trên dữ liệu huấn luyện AI tổng hợp nặng sẽ nghe phẳng hơn, bỏ qua sắc thái vùng miền và kém với từ vựng long-tail. Chi phí thể hiện ở giữ chân người dùng và nhận diện thương hiệu.
Chi phí ba: nợ mô hình dồn tích. Mỗi lần huấn luyện lại trên dữ liệu huấn luyện AI tổng hợp rẻ hơn lại thu hẹp phân phối thêm. Chi phí vô hình theo quý nhưng tích lũy thành trần thực cho thế hệ mô hình tiếp theo.
Những gì đáng theo dõi trong 12 tháng tới
Có ba điểm đáng theo dõi. Một, liệu các phương án giảm thiểu cho dữ liệu huấn luyện AI tổng hợp có cải thiện không. Có lộ trình kỹ thuật khả dĩ để thu hẹp khoảng cách thêm, thông qua thước đo chất lượng tốt hơn, bộ phân loại phát hiện tốt hơn, và ensembling ở quy mô lớn, và bất cứ tiến bộ nào theo các hướng đó cũng làm giảm phần "phụ phí" của dữ liệu con người. Hai, liệu bên mua dữ liệu tiếng Việt có thay đổi cách ký hợp đồng không.
Việc dịch chuyển từ giá theo từng tác vụ sang gói thuê bao quyền truy cập mạng lưới cộng tác viên sẽ là một tín hiệu cho thấy phía mua đang nội hóa kết quả này. Ba, liệu cơ quan quản lý ở Hà Nội có bắt đầu coi nguồn gốc dữ liệu huấn luyện là vấn đề tuân thủ không. Hiện tại thì chưa.
Tạm thời, kết luận thực tế không lãng mạn lắm. Dữ liệu huấn luyện AI thật do con người tạo đắt là có lý do của nó, và chi phí của việc bỏ qua nó không còn là giả thuyết. Với các đội Việt Nam, vốn đang xây trên một phân phối gốc đã nhỏ sẵn, lý lẽ ủng hộ đầu tư vào hạ tầng dữ liệu con người trong nước khó phản bác hơn nhiều so với một năm trước.
Câu hỏi thường gặp về dữ liệu huấn luyện AI

Dữ liệu huấn luyện AI tổng hợp có hoàn toàn không dùng được không?
Không hoàn toàn. Dữ liệu tổng hợp có ích trong một số trường hợp cụ thể: tăng cường tập dữ liệu nhỏ, tạo các tình huống hiếm gặp mà dữ liệu thực không có, và kiểm tra hệ thống trong môi trường sandbox. Vấn đề phát sinh khi các đội AI dùng dữ liệu huấn luyện AI tổng hợp làm nguồn chính, đặc biệt với tiếng Việt - ngôn ngữ vốn đã thiếu nguồn dữ liệu chất lượng cao.
Chi phí thu thập dữ liệu huấn luyện AI từ con người ở Việt Nam là bao nhiêu?
Chi phí phụ thuộc vào loại tác vụ và mức độ chuyên môn cần thiết. Với annotation văn bản thông thường, mức giá dao động từ 0,5 đến 2 USD per task tùy độ phức tạp. Với các tác vụ đòi hỏi chuyên môn cao như y tế, pháp lý, hay tài chính, chi phí có thể cao hơn 5 đến 10 lần. Quy trình kiểm soát chất lượng thường chiếm 20 đến 30% tổng ngân sách dữ liệu huấn luyện AI.
Tại sao dữ liệu huấn luyện AI tiếng Việt khó hơn tiếng Anh?
Tiếng Việt là ngôn ngữ thanh điệu với 6 thanh, cấu trúc ngữ pháp khác biệt hoàn toàn so với tiếng Anh, và có nhiều phương ngữ vùng miền. Các mô hình LLM sinh ra dữ liệu huấn luyện AI tiếng Việt thường mắc lỗi thanh điệu và dùng cấu trúc câu theo kiểu dịch máy. Những lỗi tinh vi này rất khó phát hiện bằng bộ lọc tự động nhưng ảnh hưởng lớn đến chất lượng mô hình cuối cùng.
Các startup AI Việt Nam nên xây dựng chiến lược dữ liệu huấn luyện AI như thế nào?
Bắt đầu bằng cách xác định rõ tác vụ cốt lõi và mức chất lượng dữ liệu cần thiết. Không phải mọi ứng dụng đều yêu cầu dữ liệu huấn luyện AI chất lượng cao - một chatbot hỗ trợ đơn giản có thể dùng dữ liệu tổng hợp nhiều hơn so với hệ thống phân tích tài chính. Tiếp theo, xây dựng đội annotation nội bộ nhỏ để kiểm soát chất lượng trước khi mở rộng qua đối tác bên ngoài. Cuối cùng, theo dõi sát chi phí thực tế theo từng giai đoạn thay vì ước tính gộp từ đầu.
Tài liệu tham khảo
Zhang, J., Qiao, D., Yang, M., & Wei, Q. (2024). Regurgitative Training: The Value of Real Data in Training Large Language Models. arXiv:2407.12835. https://arxiv.org/abs/2407.12835
Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., & Gal, Y. (2024). AI models collapse when trained on recursively generated data. Nature.
QuestLab. (Truy cập 5/2026). QuestLab: Vietnam's Leading Community Data Platform. https://questlab.vn





Để lại một bình luận
Bạn phải đăng nhập để gửi bình luận.