TL;DR (Tóm tắt cho kỹ sư bận rộn)
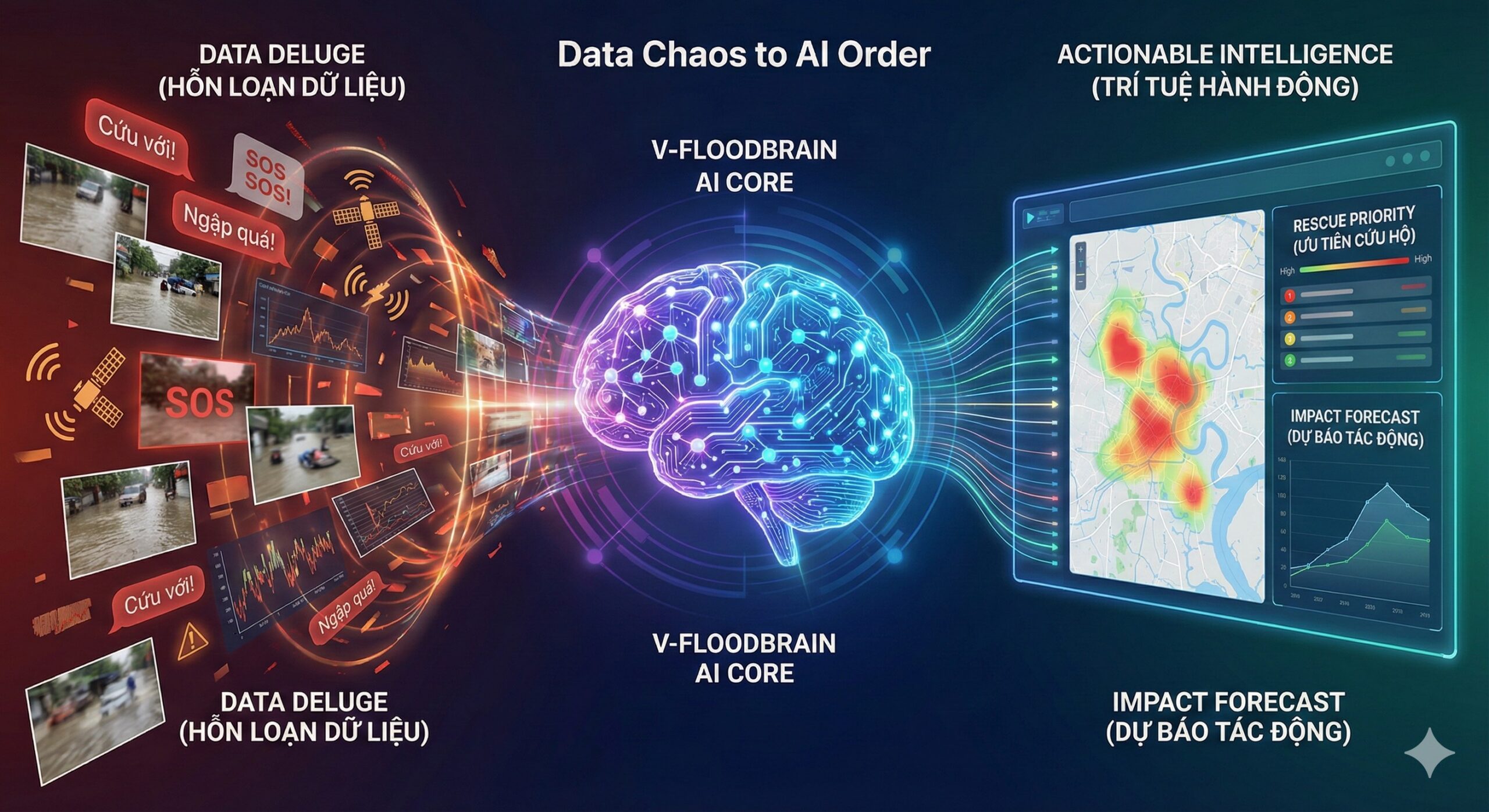
- Vấn đề từ Kỳ 2: Khi mạng lưới Mesh (V-FloodNet) được kích hoạt, trung tâm điều hành sẽ đối mặt với một "cơn hồng thủy dữ liệu" (Data Deluge) phi cấu trúc từ hàng nghìn tin nhắn SOS, ảnh chụp và cảm biến.
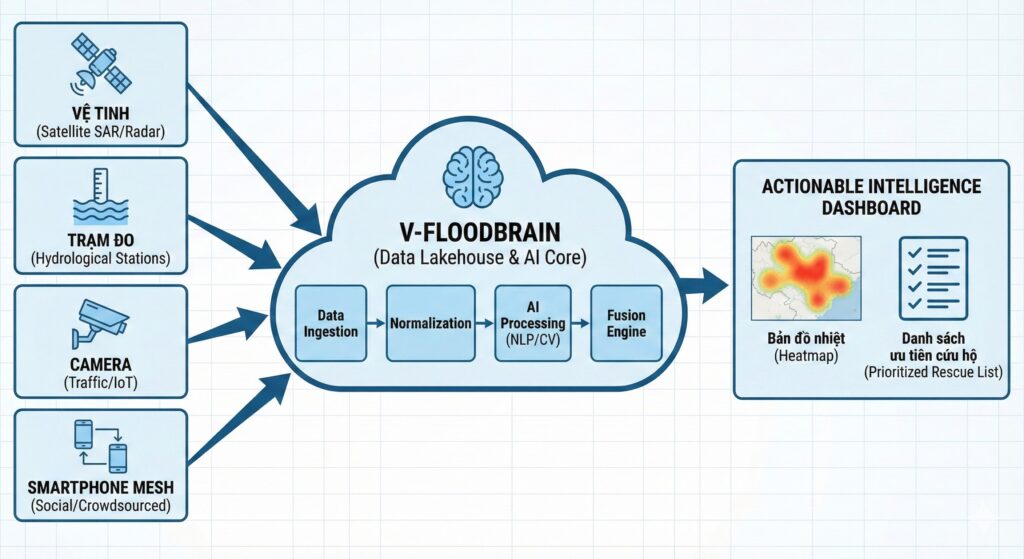
- Giải pháp Kiến trúc: Xây dựng V-FloodBrain – một hệ thống trung tâm đóng vai trò "Bộ não số", sử dụng chiến lược Hợp nhất Dữ liệu (Data Fusion) để tổng hợp 4 nguồn thông tin rời rạc (Vệ tinh, Trạm đo, IoT, Mạng xã hội/Mesh).
- Động cơ Xử lý (AI Engine):
- Sử dụng NLP (ví dụ: PhoBERT) và cơ chế Active Learning để tự động phân loại độ khẩn cấp và trích xuất thực thể (địa chỉ, nhu cầu) từ tin nhắn văn bản.
- Sử dụng Computer Vision để biến camera đường phố và ảnh chụp từ người dân thành "cảm biến mực nước ảo".
- Đầu ra: Chuyển dịch từ dự báo khí tượng sang Dự báo tác động thời gian thực (Nowcasting), cung cấp thông tin chính xác đến cấp độ con phố cho lực lượng cứu hộ.
1. Lời dẫn: Khi kết nối trở thành gánh nặng
Trong Kỳ 2: Hạ tầng phân tán, chúng ta đã thiết kế thành công V-FloodNet – một mạng lưới sinh tồn có khả năng duy trì kết nối cơ bản ngay cả khi hạ tầng viễn thông quốc gia sụp đổ. Chúng ta đã xây xong những "đường ống" dẫn tin.
Nhưng một vấn đề mới, nghiêm trọng không kém, lập tức nảy sinh. Hãy tưởng tượng kịch bản: Bão đổ bộ, nước dâng nhanh trong đêm. Mạng Mesh hoạt động và chỉ trong 1 giờ đầu tiên, 50.000 tin nhắn SOS đổ về trung tâm điều hành.
- "Cứu với, ngõ 68 Cầu Giấy nước ngập rồi." (Thông tin thiếu: Ngập bao nhiêu? Có người già trẻ em không?)
- "Nhà tôi bị cô lập, có người bị thương nặng cần y tế gấp!" (Thông tin khẩn cấp, nhưng vị trí không rõ ràng).
- Hàng nghìn bức ảnh chụp cảnh ngập lụt được gửi kèm, tối tăm và mờ mịt.
Nếu xử lý thủ công (Manual Processing), đội ngũ trực ban sẽ bị quá tải ngay lập tức. Độ trễ trong việc đọc, xác minh và phân loại tin nhắn sẽ dẫn đến những quyết định sai lầm chết người. Chúng ta có kết nối, nhưng chúng ta vẫn bị "mù" thông tin.
Kỳ 3 này sẽ đi sâu vào tầng Logic (Logical Layer): Làm thế nào để xây dựng một "Bộ não số" (V-FloodBrain) có khả năng tự động lọc nhiễu, hiểu ngữ nghĩa và biến dữ liệu thô thành mệnh lệnh hành động?
2. Kiến trúc V-FloodBrain: Chiến lược Hợp nhất Dữ liệu (Data Fusion)
Vấn đề cốt lõi của dữ liệu thiên tai hiện nay không phải là thiếu, mà là sự phân mảnh và không đồng nhất. Chúng ta đang sở hữu "4 con mắt" nhìn vào thảm họa, nhưng mỗi con mắt lại nhìn một hướng và nói một ngôn ngữ khác nhau.
2.1. Nghịch lý "4 Con Mắt" (The 4-Eyes Paradox)
| Nguồn Dữ liệu (The Eye) | Đặc điểm Kỹ thuật | Ưu điểm | Nhược điểm Chí mạng (Fatal Flaw) |
| 1. Mắt Thần (Vệ tinh SAR, Radar thời tiết) | Macro-scale, Remote Sensing | Độ phủ rộng toàn vùng/quốc gia. Nhìn xuyên mây (với SAR). | Độ phân giải thời gian thấp. Ảnh vệ tinh thường trễ 6-12h. Không hữu ích cho ứng cứu khẩn cấp tức thời. |
| 2. Mắt Chính thống (Trạm quan trắc thủy văn) | Precise Point Data, Structured | Độ chính xác cực cao (Gold Standard). Dữ liệu có cấu trúc, dễ xử lý. | Độ phủ không gian quá thưa. Một trạm đo mực nước sông không đại diện cho tình trạng ngập tại một con ngõ cách đó 5km. |
| 3. Mắt Đô thị (Camera giao thông, IoT cảm biến) | Visual/Sensor Data, Localized | Trực quan, thời gian thực tại các điểm nóng đô thị. | Cục bộ và dễ tổn thương. Phụ thuộc vào điện lưới. Camera thường bị mờ khi mưa lớn hoặc mất tác dụng vào ban đêm. |
| 4. Mắt Dân sinh (Mạng xã hội, Mạng Mesh) | Crowdsourced, Unstructured text/image | Thời gian thực, độ phủ siêu cao (Hyper-local). Có mặt ở mọi ngóc ngách. | Độ nhiễu cực cao (High Noise Ratio). Tin rác, tin giả, tin trùng lặp. Dữ liệu phi cấu trúc khó xử lý. |
Nhận định Kỹ thuật: "Một hệ thống hiệu quả không thể dựa vào một nguồn duy nhất. Nó phải là sự Hợp nhất (Fusion). V-FloodBrain là kiến trúc Data Lakehouse để thu nhận tất cả các luồng dữ liệu này, chuẩn hóa chúng và đưa vào các mô hình AI xử lý."
3. Deep Dive: Động cơ AI – Xử lý Dữ liệu Phi cấu trúc
Thách thức lớn nhất nằm ở nguồn dữ liệu số 4: Mắt Dân sinh. Đây là nguồn dữ liệu phong phú nhất nhưng cũng "bẩn" nhất. Để khai thác nó, chúng ta cần hai mũi nhọn công nghệ: NLP (cho văn bản) và Computer Vision (cho hình ảnh).
3.1. NLP Pipeline: Hiểu tiếng kêu cứu của người Việt
Xử lý tin nhắn SOS trong bão lũ khác hoàn toàn với việc phân tích cảm xúc (Sentiment Analysis) trên thương mại điện tử. Nó đòi hỏi độ chính xác cực cao trong môi trường nhiễu và áp lực thời gian.
A. Thách thức Ngôn ngữ (Linguistic Challenges):
- Tính đa nghĩa và khẩn cấp: Cụm từ "nước lên rồi" có thể là thông báo bình thường, nhưng "nước ngập đến cổ rồi, cứu với" là khẩn cấp tối đa. AI phải hiểu được sắc thái này.
- Tiếng Việt không dấu và viết tắt: Trong lúc hoảng loạn, người dân thường nhắn không dấu, viết tắt (vd: "ngap qua roi, cuu e o 58 ng chi thanh").
- Địa danh địa phương: Các tên gọi dân gian (ví dụ: "cống ông Bảy") không có trên bản đồ Google Maps.
B. Giải pháp Kỹ thuật: Transformer và Active Learning
Thay vì các mô hình dựa trên từ khóa (Keyword-based) thô sơ, V-FloodBrain cần triển khai các mô hình Transformer tiên tiến, cụ thể là các biến thể đã được tiền huấn luyện (pre-trained) cho tiếng Việt như PhoBERT hoặc ViBERT.
- Bước 1: Intent Classification (Phân loại Ý định & Độ khẩn cấp):Mô hình sẽ phân loại tin nhắn vào các nhóm ưu tiên:
- Priority 1 (Critical): Đe dọa tính mạng (người già, trẻ em, y tế, nước dâng nhanh).
- Priority 2 (High): Cần sơ tán, thiếu lương thực/nước sạch.
- Priority 3 (Info): Báo cáo tình hình, chưa cần cứu hộ ngay.
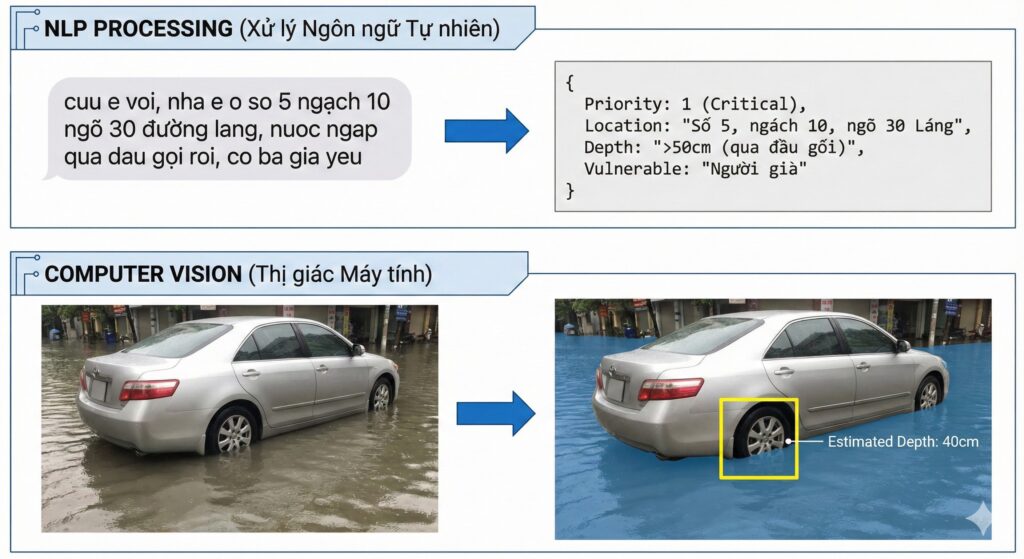
- Bước 2: Named Entity Recognition (NER - Trích xuất Thực thể):Mô hình tự động trích xuất các trường thông tin quan trọng để điền vào cơ sở dữ liệu có cấu trúc:[Địa chỉ chính xác], [Số lượng người], [Số điện thoại liên hệ], [Loại nhu cầu].
- Bước 3: Cơ chế Active Learning (Học chủ động) trong thời gian thực:Đây là chìa khóa. Trước khi bão đến, chúng ta không có đủ dữ liệu huấn luyện (labeled data) hoàn hảo.Hệ thống sẽ hoạt động theo mô hình "Human-in-the-loop":
- AI tự tin xử lý 80% tin nhắn dễ.
- 20% tin nhắn khó, mơ hồ được đẩy sang cho tình nguyện viên số (Digital Volunteers) gán nhãn thủ công.
- Dữ liệu mới được gán nhãn này lập tức được dùng để huấn luyện lại (Retrain) mô hình sau mỗi vài giờ, giúp AI thông minh lên nhanh chóng ngay trong diễn biến của cơn bão.
3.2. Computer Vision: Biến mọi bức ảnh thành cảm biến
Hàng nghìn bức ảnh chụp cảnh ngập lụt được gửi về chứa đựng thông tin quý giá về mực nước thực tế, nhưng máy tính không hiểu được.
Giải pháp: Semantic Segmentation & Reference Objects
Chúng ta không cần nhận diện khuôn mặt, chúng ta cần nhận diện mực nước. Mô hình Computer Vision sẽ được huấn luyện để:
- Phân đoạn ảnh (Segmentation): Tách biệt vùng nước, vùng đất, và các vật thể.
- Tìm vật chuẩn (Reference Objects): Nhận diện các vật thể có kích thước chuẩn trong ảnh như: bánh xe ô tô, biển báo giao thông, cột điện, vỉa hè.
- Ước tính độ sâu (Depth Estimation): Dựa vào tỷ lệ phần vật chuẩn bị chìm trong nước để tính toán ra độ sâu ngập tương đối (ví dụ: ngập 1/2 bánh xe sedan ~= 30cm).
Ứng dụng thực tiễn: "Khi một người dân gửi ảnh chụp con phố ngập nước. AI tự động phân tích và báo về trung tâm: 'Địa điểm X, ước tính ngập 45cm, phương tiện gầm thấp không thể tiếp cận'. Điều này giúp điều phối đúng loại phương tiện cứu hộ (xuồng máy thay vì xe tải)."
4. Đầu ra: Từ Dự báo Khí tượng sang Dự báo Tác động (Impact-based Forecasting)
Mục tiêu cuối cùng của V-FloodBrain không chỉ là phản ứng lại những gì đã xảy ra, mà là dự báo những gì sắp xảy ra trong kịch bản siêu cục bộ (Hyper-local).
Hệ thống khí tượng hiện tại cho chúng ta biết: "Quận Cầu Giấy sẽ mưa 100mm trong 3 giờ tới". Thông tin này quá chung chung.
Bằng cách kết hợp dữ liệu thời gian thực từ Mạng Mesh (đang mưa bao nhiêu tại chỗ), dữ liệu địa hình 3D của thành phố, và lịch sử ngập lụt, AI có thể chạy các mô hình thủy lực học tốc độ cao (Surrogate Models) để đưa ra Dự báo tác động (Nowcasting):
"Cảnh báo: Với lượng mưa hiện tại, tuyến phố Thái Hà đoạn từ ngõ 1 đến ngõ 5 sẽ ngập sâu 60cm trong 45 phút tới. Các phương tiện cần di dời ngay lập tức."
Đây là sự chuyển dịch từ việc thông báo các con số khí tượng vô hồn sang các cảnh báo hành động cụ thể, giúp giảm thiểu thiệt hại về người và của.
5. Kết luận Kỳ 3 & Cầu nối sang Kỳ cuối
V-FloodBrain là mảnh ghép còn thiếu để biến dữ liệu thô thành trí tuệ hành động. Nó kết nối sự dũng cảm của người dân tại hiện trường (cung cấp dữ liệu) với năng lực chỉ huy của chính quyền.
Tuy nhiên, một hệ thống AI mạnh mẽ như vậy cần nguồn nguyên liệu đầu vào khổng lồ. Nó cần quyền truy cập vào dữ liệu camera giao thông thời gian thực, dữ liệu bản đồ số độ phân giải cao, và dữ liệu trạm đo mưa của nhà nước.
Vấn đề kỹ thuật đã được giải quyết, giờ là lúc đối mặt với rào cản lớn nhất: Cơ chế và Chính sách. Làm sao để phá vỡ các "lô cốt" dữ liệu giữa các bộ ban ngành và giữa nhà nước với cộng đồng công nghệ?
ĐÓN ĐỌC KỲ CUỐI: CHÍNH SÁCH DỮ LIỆU & LỜI HIỆU TRIỆU HÀNH ĐỘNG.
Chúng ta sẽ thảo luận về mô hình "Chính phủ là Nền tảng" (Gov as a Platform), đề xuất mở API dữ liệu thiên tai (Open Data), và vai trò cụ thể mà cộng đồng công nghệ (Civic Tech) có thể đóng góp ngay bây giờ.
Nếu bạn chưa đọc các kỳ trước
- Bạn chưa rõ tại sao chúng ta cần mạng lưới mới? Xem lại 🔙 [Kỳ 1: Phân tích sự cố hệ thống].
- Bạn muốn tìm hiểu kỹ thuật xây dựng hạ tầng kết nối khi mất điện? Xem lại 🔙 [Kỳ 2: Hạ tầng phân tán (Mesh Network)].





Để lại một bình luận
Bạn phải đăng nhập để gửi bình luận.