TL;DR: FPT Corporation and Nvidia released 900,000 synthetic Vietnamese personas on June 5, 2026 - free for commercial use. These synthetic Vietnamese personas accelerate AI model training and survey pre-testing. However, for compliance workflows, credit decisioning, and B2B analytics, verified data from real-world sources remains essential - and that distinction matters more than ever as Vietnam enforces Circular 50 from July 1, 2026.
What are synthetic Vietnamese personas?
On June 5, 2026, FPT Corporation and Nvidia jointly released the Nemotron-Personas-Vietnam dataset on Hugging Face: 900,000 synthetic Vietnamese personas covering name, age, location, occupation, income, and marital status across 31 structured fields. The dataset uses a CC-BY-4.0 license allowing free commercial use with attribution.
The Nemotron methodology, developed by Nvidia and validated by FPT's Quantum AI and Cyber Security Institute, grounds each persona in Vietnam's official demographic statistics and geographic structure. These are not random data points - they are statistically calibrated profiles designed to reflect how Vietnamese people actually live, work, and communicate.
Vietnam is now part of Nvidia's global Nemotron-Personas collection, which already covers the US, Singapore, and South Korea. That positions Vietnam as a priority AI market and gives every developer, researcher, and enterprise in the country access to a free population-scale training corpus in Vietnamese.
Where do synthetic Vietnamese personas excel?
Synthetic personas shine in the development and testing phases of AI systems. Specifically, they are valuable for:
- Language model training and fine-tuning - a Vietnamese-language chatbot or NLP model trained on 900,000 diverse demographic profiles will generalize better across age groups, regions, and occupations than one trained on limited data.
- Survey instrument pre-testing - a survey platform can run a questionnaire against a synthetic panel before committing fieldwork budget, catching confusing questions or demographic blind spots early.
- Onboarding flow testing - product teams can stress-test registration and onboarding flows across the full Vietnamese demographic range without touching real customer data.
- Bias detection in AI models - developers can check whether their model performs consistently across provinces, income bands, and age groups before going to production.
These use cases are real and valuable. The release significantly lowers the barrier to building AI systems that are actually calibrated to Vietnamese users.
Where do synthetic Vietnamese personas stop?
Starting January 2026, Vietnamese banks must verify customer biometrics before activating any new bank account or payment card. From July 1, 2026, Circular 50/2024/TT-NHNN (Thong tu 50/2024/TT-NHNN) mandates ISO 30107-3 presentation attack detection (PAD) certification for all online banking service providers in Vietnam.
A synthetic Vietnamese persona cannot satisfy either requirement. A synthetic persona cannot confirm whether a specific company at a specific address is actively registered with the Department of Planning and Investment (Bo Ke hoach va Dau tu). A synthetic identity cannot be cleared from a financial intelligence unit watchlist. A synthetic occupation field cannot verify whether an employer is a real, tax-registered entity.
Production compliance systems, credit decisioning models, fraud detection pipelines, and B2B identity workflows all require verified, structured data sourced from real-world registries - not statistical approximations. Synthetic training data helps you build the model. Verified data is what the model runs against when real customers show up.
The verified data layer that completes the picture
Vietnam now has both layers of the AI data stack. Open synthetic datasets like Nemotron-Personas-Vietnam accelerate development velocity and reduce the cost of building Vietnamese-language AI. Verified data infrastructure makes production systems defensible under Vietnamese law and international compliance standards. They are not competitors - they operate at different stages of the AI development lifecycle.
DataCore's Address Service, Company Intelligence Service, and eKYC Service provide the verification layer: real address records, active company registrations, and biometric-grade identity verification built for Vietnam's 2026 regulatory environment. As more developers build on synthetic Vietnamese data foundations, the demand for a reliable enrichment and verification layer grows alongside it.
Related: Vietnam's AI Strategy and the Missing Data Infrastructure Piece - Why Vietnamese SMEs Cannot Get Credit - and What Structured Company Data Fixes
Frequently asked questions
What is Nemotron-Personas-Vietnam?
Nemotron-Personas-Vietnam is a dataset of 900,000 synthetic Vietnamese personas released by FPT Corporation and Nvidia on June 5, 2026. Each persona contains 31 fields including demographic, occupational, and geographic attributes, grounded in Vietnam's official national statistics. It is available free for commercial use under a CC-BY-4.0 license on Hugging Face.
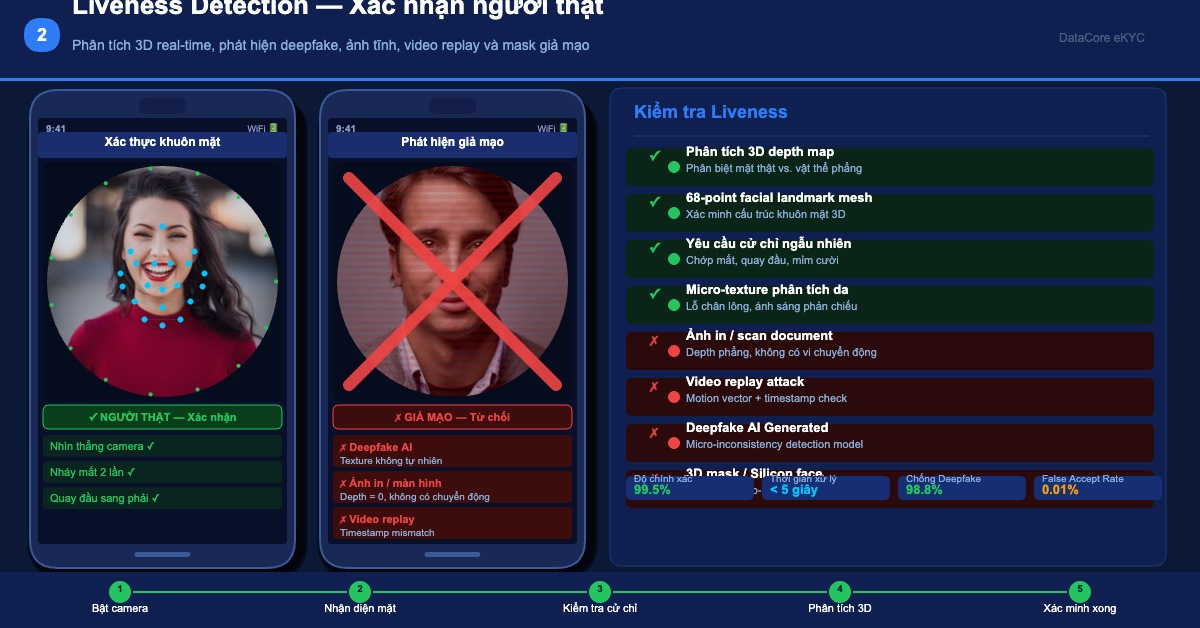
Can synthetic Vietnamese personas be used for eKYC verification?
No. Synthetic personas are generated from statistical distributions, not real identity records. Vietnam's eKYC requirements under Circular 50/2024/TT-NHNN require biometric verification against real identity databases. Synthetic personas can be used to train and test eKYC models, but cannot be used as the verification layer itself.
What is the difference between synthetic data and verified data in Vietnam?
Synthetic data is AI-generated based on statistical models - useful for training, testing, and development. Verified data comes from real-world sources such as the national business registry, tax authority, and official identity databases - required for compliance, credit decisions, and legally defensible workflows under Decree 13/2023/ND-CP and related regulations.
How does DataCore's data differ from the Nemotron-Personas-Vietnam dataset?
DataCore's data products - including the Address Service, Company Intelligence Service, and eKYC Service - are sourced from real Vietnamese registries, verified against official databases, and maintained with active update cycles. They are built for production compliance and B2B analytics workflows, not for AI model training. The two are complementary: synthetic personas for development, DataCore for production.
How to build a compliant AI pipeline with synthetic Vietnamese personas and verified data
The practical question for Vietnamese AI teams is not whether to use synthetic Vietnamese personas - it is how to combine them correctly with verified data at each stage of the pipeline. Here is the architecture that works for the 2026 regulatory environment.

Step 1: Use synthetic Vietnamese personas at training time
The 900,000 synthetic Vietnamese personas in Nemotron-Personas-Vietnam give AI teams a statistically grounded training corpus without the PDP compliance burden of collecting real personal data. Use them for: fine-tuning NLP models on Vietnamese demographic patterns, building training sets for credit scoring and risk models, testing survey instrument validity across age, province, and occupation groups, and stress-testing onboarding flows against the full range of Vietnamese demographic combinations.
Synthetic Vietnamese personas are purpose-built for this phase. FPT's DC5 field surveys and Nvidia's NeMo Data Designer methodology ensure the demographic distributions match Vietnam's official statistics. For pre-production testing and model training, the quality is sufficient and the CC-BY-4.0 license removes attribution barriers.
Step 2: Switch to verified data at inference time
When a real customer submits a real identity document, synthetic Vietnamese personas are not the right verification tool. The production layer requires data verified against real registries: company registration databases, postal address systems, and certified identity graphs. Each synthetic persona field maps to a verified-data equivalent at inference time.
For the occupation field: synthetic Vietnamese personas include occupation and employer-type data that is statistically calibrated but not verified against real business registrations. At production time, DataCore's Company Intelligence Service confirms whether the employer is a real, actively registered business in Vietnam's company database. For the address field: the synthetic personas include province and district data grounded in Vietnam's administrative geography. DataCore's Address Service verifies whether a specific address is real, deliverable, and formatted to current post-merger administrative standards. For identity: synthetic Vietnamese personas do not exist in any real identity registry. DataCore's eKYC Service verifies real biometric identity against certified databases, meeting Circular 50/2024/TT-NHNN's ISO 30107-3 PAD certification requirements.
Step 3: Document the boundary clearly for compliance
Vietnam's Decree 13/2023/ND-CP on personal data protection and Circular 50's biometric authentication requirements create clear documentation obligations. Compliance audits will ask two questions: what data was used to train the model, and what data is used to make production decisions. Synthetic Vietnamese personas provide a clean answer to the first question - CC-BY-4.0, FPT and Nvidia, open source, no PII involved. Verified data from real registries provides the answer to the second question. The two layers are complementary, not interchangeable. Blending them without a clear architectural boundary creates compliance risk at both ends.

How Verified Data Infrastructure Handles the Synthetic Data Gap
The release of Nemotron-Personas-Vietnam highlights a structural gap that every Vietnamese fintech, insurtech, and enterprise data team will face in 2026: synthetic data is abundant, but verification infrastructure is scarce. Bridging that gap requires more than a dataset. It requires a data layer that can validate, enrich, and contextualize synthetic outputs against real-world ground truth.
Here is how that bridge works in practice across the four scenarios where synthetic Vietnamese personas are most likely to be deployed.
Scenario 1: eKYC Model Training and Validation
Financial institutions building eKYC systems under Circular 50/2024/TT-NHNN (Vietnam State Bank, effective July 1, 2026) need hundreds of thousands of labeled face images, liveness detection samples, and document scans. Synthetic personas can generate the volume. But the model still needs to be calibrated against real CCCD data formats, real lighting conditions, and real failure modes from Vietnamese identity documents issued across 63 provinces.
Verified data fills three roles here: it provides the ground-truth calibration set, it supplies the negative examples (fraudulent submissions, edge-case document variants), and it validates that the trained model behaves correctly on real inputs before deployment. A model trained exclusively on synthetic data and never benchmarked against verified real-world data is a liability risk, not a compliance solution.
Scenario 2: Credit Decisioning for Underbanked Segments
Vietnam's credit bureau coverage is estimated at around 50 to 55 percent of the adult population as of 2025. The remaining 45 to 50 percent are underbanked or credit-invisible. Synthetic persona datasets like Nemotron can model income, spending behavior, and financial attitudes for this segment. But a credit model built on synthetic inputs alone has no anchor to actual repayment behavior.
The production-grade approach is a two-layer architecture: synthetic data builds the prior (the base model that handles sparse inputs), and verified transactional data from telco billing, utility payments, e-wallet histories, and property registries updates the posterior (the real-world correction). Neither layer is sufficient alone. Together they produce a model that scores thin-file applicants without the bias that comes from extrapolating solely from existing banked populations.
Scenario 3: B2B Market Segmentation and Lead Scoring
Enterprise software vendors, insurance companies, and data platform providers targeting Vietnamese businesses need reliable company intelligence. Synthetic persona data covers the individual (age, profession, digital behavior, stated preferences). But B2B decisions are made by organizations, not individuals, and organizations have attributes that cannot be synthesized: registered capital, actual revenue, tax filing status, active trade relationships, and legal standing.
Verified company data from Vietnam's enterprise registries, tax authority, and legal records databases provides the organizational layer that synthetic personas cannot replicate. When you overlay synthetic individual behavior data on verified company-level data, you get a segmentation model that can predict both who is likely to buy and whether the organization has the financial health to actually execute a contract.
Scenario 4: Regulatory Stress Testing and Model Risk Management
Vietnam's financial regulators are increasingly requiring institutions to demonstrate model robustness across demographic and geographic segments. Synthetic data is valuable here because it lets you generate stress scenarios for segments that are underrepresented in your historical data. But the stress test results still need to be validated against real outcomes data to satisfy a regulator.
A model that performs well on synthetic stress scenarios and poorly on historical verified data tells you the synthetic distribution was wrong. A model that performs well on historical data but has never been tested on synthetic edge cases tells you it may fail on novel populations. Both inputs are necessary. The documentation trail for regulators requires both as well - you cannot present a synthetic-only validation package to Vietnam's State Bank and expect approval.
What to Look for in a Verified Data Partner
Not all verified data providers are equal. For Vietnamese enterprises considering how to complement synthetic persona datasets, the evaluation criteria should include the following.
Coverage depth across provinces and demographics. Vietnam's 63 provinces have significantly different data availability profiles. A data provider that covers Ho Chi Minh City and Hanoi well but has thin coverage in Mekong Delta provinces will create systematic blind spots in any model you build. Ask for coverage statistics by province before signing a data contract.
Update frequency and as-of dating. Verified data that is 18 months old is not verified data in any meaningful sense for credit or compliance applications. Look for providers who publish explicit update schedules for each data product and who include an as-of date in every data export. Undated data is a red flag.
Legal basis for collection and sharing. Vietnam's Personal Data Protection Decree 13/2023/ND-CP requires an explicit legal basis for collecting, processing, and sharing personal data. Verified data providers operating legally in Vietnam should be able to demonstrate their legal basis for each data category they offer. If a provider cannot produce documentation, the data carries regulatory risk for you as the recipient.
API access and integration quality. Verified data is only useful if it can be queried at the point of decision. Batch-only data delivery works for model training but not for real-time eKYC or credit decisioning. Look for providers with documented REST APIs, sub-second response times for core queries, and SLAs that specify uptime and data freshness guarantees.
Frequently Asked Questions: Synthetic Data vs. Verified Data in Vietnam
Is Nemotron-Personas-Vietnam compliant with Decree 13/2023/ND-CP?
The dataset is fully synthetic - no real individuals appear in it. It does not contain personal data as defined under Decree 13. However, any model trained on this data and then deployed to process real Vietnamese personal data would still need to comply with Decree 13 requirements for the processing activity itself. The synthetic training data is outside scope; the deployed model's use of real data is inside scope.
Can synthetic Vietnamese personas replace real data for ISO 30107-3 PAD certification?
No. ISO 30107-3 Presentation Attack Detection certification requires testing against real attack scenarios recorded with real presentation attack instruments. Synthetic personas can help build the underlying biometric model, but the certification test set must include real PAD samples. Circular 50/2024/TT-NHNN mandates ISO 30107-3 compliance for online banking channels from July 1, 2026, so this is not a theoretical distinction.
How does DataCore's verified data compare to the Nemotron synthetic dataset?
They serve different purposes. Nemotron-Personas-Vietnam is a synthetic dataset designed for AI model training at scale. DataCore provides verified real-world data from Vietnamese registries, financial records, and business databases - data that reflects actual entities, actual transactions, and actual legal status. The two are complementary: synthetic data for training volume and coverage, verified data for calibration, validation, and production enrichment.
What is the typical integration timeline for adding verified data to an existing AI pipeline?
For teams with existing ML infrastructure, the integration typically takes 2 to 4 weeks: API access and authentication setup (2 to 3 days), data mapping and schema alignment (3 to 5 days), pipeline integration and testing (5 to 10 days), and production validation (3 to 5 days). The main variable is how far the verified data schema diverges from the training data schema. DataCore provides integration documentation and a sandbox environment to accelerate the mapping phase.





Để lại một bình luận
You must be logged in to post a comment.